最新Java面试题全集
JDK、JRE、JVM之间的区别
JVM是执行字节码的引擎,是运行程序的基础。
JRE = JVM + 核心类库,它是运行 Java 程序的最小环境。
单靠 JVM 是运行不了复杂的 Java 字节码程序的,比如 HTTP 请求,数据库连接等等。
java.lang.Object 类也位于核心类库中,所以即使只运行一个执行基本类型的加法操作的 main 方法时,也需要使用 JRE 来运行。
因为你定义的包含 main 方法的类也会隐式的继承 java.lang.Object 类。
JDK = JRE + 开发工具(主要是编译器 javac)。它是开发 Java 程序的完整套件。 换句话说,如果你是开发者,需要编写代码、编译代码,那么你需要安装 JDK。 如果你只是最终用户,需要运行一个 Java 程序,你只需要安装 JRE。
hashCode()与equals()之间的关系
在 Java 中,每个对象都可以调用自己类中的 hashCode() 方法得到自己的哈希值(hashCode),相当于对象的指纹信息。
通常来说世界上没有完全相同的两个指纹,但是在 Java 中做不到这么绝对,但是仍然可以利用 hashCode 来做一些提前的判断,规则如下:
- 如果两个对象的
hashCode 不相同,那么这两个对象肯定是不同的两个对象。 - 如果两个对象的
hashCode 相同,那么这两个对象可能是相同的。 - 如果两个
对象相等,那么它们的hashCode就一定相同。
在 Java 的一些集合类的实现中,通常会根据上面的原则来进行比较对象是否相同:
- 先调用对象的 hashCode() 方法得到 hashCode 进行比较,如果 hashCode 不相同,就可以直接认为这两个对象不相同。
- 如果 hashCode 相同,那么就会进一步调用 equals() 方法进行比较,就是用来确定两个对象是不是相等的。
WARNING
如果我们重写了 hashCode()、equals() 方法,那么就要注意,一定要保证能遵循上述规则。
为什么判断对象是否相同时,都会先使用 hashCode() 判断?
通常 equals 方法的实现会比较重,逻辑比较多,而 hashCode() 主要就是得到一个哈希值,实际上就一串数字,相比而言较轻,所以在比较两个对象时,通常会先根据 hashCode 比较一下。
String、StringBuffer、StringBuilder的区别
| 特性 | String | StringBuffer | StringBuilder |
|---|---|---|---|
| 可变性 | 不可变(Immutable) 创建后内容不能修改 | 可变(Mutable) 内容可以通过方法修改 | 可变(Mutable) 内容可以通过方法修改 |
| 线程安全 | 本身不可变,天然安全 | 安全(Synchronized) 方法用synchronized修饰 | 不安全(非同步) 没有锁,性能更高 |
| 性能 | 拼接时效率最低 (大量新建对象) | 效率中等 (有同步开销) | 效率最高 (无锁) |
| 适用场景 | 1. 定义常量字符串 2. 不需要频繁修改 | 1. 多线程环境下字符串频繁修改 2. 需要线程安全 | 1. 单线程环境下字符串频繁修改 2. 需要最高性能 |
| 继承关系 | 直接继承Object | 继承AbstractStringBuilder | 继承AbstractStringBuilder |
为什么在编码中,还是用 String 直接拼接的情况更多?
Java 编译器自动优化了静态字符串拼接,编译器能确定内容的拼接,JVM会自动优化,不存在性能问题。
javaString s = "a" + "b" + "c";会被编译器直接优化为 "abc",不会运行时创建多个对象。
javaString s = "a" + someConstant;如果 someConstant 是常量(static final),也会被优化。
线程安全不是刚需,现代开发中,大多数场景都是单线程操作(如 HTTP 请求处理)。
泛型中 extends 和 super 的区别
- ? extends T 表示包括 T 在内的任何 T 的子类
- ? super T 表示包括 T 在内的任何 T 的父类
== 和 equals() 的区别
- ==:如果是基本数据类型,比较的是值,如果是引用类型,比较的是引用地址。
- equals:
- 重写equals方法:具体看各类重写 equals 方法之后的比较逻辑,比如 String 类,虽然是引用类型,但 String 类中重写了 equals 方法,方法内部比较的是字符串中的各个字符是否全部相等。
- 未重写equals方法:如果某一个引用类型并没有重写 java.lang.Object 类的 equals 方法,那么对于该引用类型来说, equals 和 == 是相同的,因为 java.lang.Object 中 equals 方法的逻辑内部就是用 == 判断的。
重载和重写的区别
- 重载(overload):在同一个类中,
同名的方法如果满足以下任意条件之一:参数类型不同参数个数不同
- 重写(override):子类把父类本身有的方法重新写一遍。必须
满足以下所有条件:- 方法名相同
- 参数列表相同(类型、数量、顺序)
- 返回类型相同(子类中方法的返回值可以是父类中方法返回值的子类)
- 子类方法的访问修饰符权限不能小于父类
各个方法修饰符的区别
| 修饰符 | 访问级别 | 是否可被子类重写 | 是否可被同一包中的其他类访问 | 是否可被不同包中的类(通过继承)访问 | 是否可被不同包中的类(非继承)访问 |
|---|---|---|---|---|---|
public | 最高,无限制 | 是 | 是 | 是 | 是 |
protected | 次之,包内 + 子类可访问 | 是 | 是 | 是 | 否 |
默认(无修饰符)或 default | 包级私有,仅限于同一个包内 | 是 | 是 | 否 | 否 |
private | 最低,仅限于声明它的类内部 | 否 | 否 | 否 | 否 |
List 和 Set 的区别
- List
- 有序(按对象插入的顺序保存对象)
- 可重复
- 允许多个 Null 元素对象
- 可以使用 Iterator 取出所有元素,还可以使用 get(int index) 获取指定下表的元素
- Set
- 无序
- 不可重复
- 最多允许有一个 Null 元素对象
- 只可以使用 Iterator 取出所有元素,再逐一遍历各个元素
ArrayList 的底层工作原理
- 添加元素
- add(E element):在末尾添加元素的时间复杂度为 O(1),但如果需要扩容,则时间复杂度为 O(n)。
- add(int index, E element):
- 先检查是否 0 <= index <= size(),如果不符,则报 IndexOutOfBoundsException。
- 再确认数组容量是否足够容纳 size() + 1(当前元素),不够则扩容。
- 如果 index = size(),则把新元素添加到指定位置,执行结束。
- 如果 0 <= index < size(),则把新元素添加到指定位置,然后后面元素则从 index 位置依次后移。
- 获取元素 get(int index)
- 由于 ArrayList 底层是一个数组,所以通过索引直接访问元素的时间复杂度为 O(1)。
- 删除元素
- remove(int index):根据索引删除元素时,需要将被删除元素后的所有元素向前移动一位,时间复杂度为 O(n)。
- remove(Object o):使用对象进行删除时,首先需要遍历列表找到匹配项并删除,然后将被删除元素后的所有元素向前移动一位,时间复杂度同样为 O(n)。
- 数组扩容
- ArrayList 的自动扩容,只在添加元素到“末尾”时生效。
- 数组扩容数组扩容时是按 1.5 倍扩容,向下取整。
- 虽然默认扩容策略是 1.5 倍,但如果扩容后仍不够用,ArrayList 会强制将容量设为“当前所需最小容量”,因此即使初始容量为 1,也能正常扩容。
JDK8,刚创建 ArrayList 后为什么数组长度是 0,默认长度不是为 10 么?
这是 Java 8 及以后版本的优化行为:懒加载(Lazy Initialization),只有在第一次添加元素时才真正分配空间。
public static void main(String[] args) {
ArrayList<Object> list = new ArrayList<>();
print(list);
list.add("a");
print(list);
}
private static void print(ArrayList<Object> list) {
System.out.println(list);
System.out.println("元素个数" + list.size());
System.out.println("数组长度:" + getArrayListCapacity(list));
}
// 使用反射获取 elementData 的长度
private static int getArrayListCapacity(ArrayList<?> list) {
try {
java.lang.reflect.Field field = ArrayList.class.getDeclaredField("elementData");
field.setAccessible(true);
return ((Object[]) field.get(list)).length;
} catch (Exception e) {
throw new RuntimeException(e);
}
}执行以上代码时,如果使用的是 JDK9 或更新版本的 JDK,发生了以下报错:
java.lang.reflect.InaccessibleObjectException: Unable to make field transient java.lang.Object[] java.util.ArrayList.elementData accessible: module java.base does not "opens java.util" to unnamed module请添加 VM options
--add-opens java.base/java.util=ALL-UNNAMED这是因为从 Java 9 开始,Oracle 引入了模块化系统(JPMS),很多 JDK 内部类和字段默认不再对反射开放访问权限。
ArrayList 的 elementData 字段属于 java.util 包,而该包在 Java 17 及以后版本中 默认不对外开放反射访问。
[]
元素个数0
数组长度:10
[a]
元素个数1
数组长度:10ArrayList 的扩容机制
ArrayList 自动扩容报错
既然 ArrayList 能够自动扩容,为什么以下 Java 代码执行会报错?
ArrayList<Object> list = new ArrayList<>();
list.add(10, "a"); // 报错:IndexOutOfBoundsExceptionException in thread "main" java.lang.IndexOutOfBoundsException: Index: 10, Size: 0这是因为ArrayList的自动扩容,只在添加元素到“末尾”时生效。
- add(E element):因为每次都是在“末尾”添加元素,所以可以动态扩容,不需关心当前容量,不会发生 IndexOutOfBoundsException。
- add(int index, E element):如果 index != list.size(),则不会自动帮助你进行数组扩容,且
必须 0 <= index <= size(),如果 index > size(), 则会报 IndexOutOfBoundsException。
ArrayList 扩容时是新建数组还是在原数组上扩容
使用 Java 代码验证,通过反射获取 ArrayList 的底层数组地址(或对象标识),来验证扩容前后是否是同一个数组。
import java.util.ArrayList;
import java.lang.reflect.Field;
public class ArrayListExpandTest {
public static void main(String[] args) throws Exception {
ArrayList<String> list = new ArrayList<>(3);
System.out.println("初始容量: " + getCapacity(list));
printArrayIdentity(list);
// 添加元素触发扩容
list.add("A");
list.add("B");
list.add("C");
System.out.println("添加3个元素后,容量: " + getCapacity(list));
printArrayIdentity(list);
list.add("D"); // 触发扩容
System.out.println("再添加1个元素后,容量: " + getCapacity(list));
printArrayIdentity(list);
}
// 使用反射获取底层数组对象
private static Object getInternalArray(ArrayList<?> list) throws Exception {
Field field = ArrayList.class.getDeclaredField("elementData");
field.setAccessible(true);
return field.get(list);
}
// 打印数组对象的唯一标识
private static void printArrayIdentity(ArrayList<?> list) throws Exception {
Object array = getInternalArray(list);
System.out.println("当前底层数组对象 hashcode: " + array.hashCode() + "\n");
}
// 获取当前容量
private static int getCapacity(ArrayList<?> list) throws Exception {
return ((Object[]) getInternalArray(list)).length;
}
}初始容量: 3
当前底层数组对象 hashcode: 1030870354
添加3个元素后,容量: 3
当前底层数组对象 hashcode: 1030870354
再添加1个元素后,容量: 4
当前底层数组对象 hashcode: 485815673可以看到,扩容之后 hashcode 改变了 → 说明底层数组已经换了! ArrayList 在扩容时,是新建一个更大的数组,然后将原数组的内容复制到新数组中,并不是在原数组上扩容。 因为 Java 中的数组一旦创建后大小是固定的,不能动态改变长度。所以扩容的本质就是:
- 创建一个新的、更大的数组
- 把旧数组内容拷贝到新数组
- 用新数组替换原来的数组
ArrayList 和 LinkedList 的区别
- ArrayList
- 基于动态数组实现。
- 允许直接访问元素(通过索引),因为它是基于数组的,所以访问速度非常快。
- 当元素数量超过当前容量时,会自动扩容,这涉及到创建新数组并复制旧数组的内容,这个过程比较耗时。
- LinkedList
- 基于双向链表实现。
- 不支持随机访问,要访问某个元素必须从头或尾开始遍历链表,直到找到目标元素。
- 插入和删除操作不需要移动其他元素,只需改变相关节点的指针即可,所以在插入和删除操作上效率较高。
ConcurrentHashMap 扩容机制
多线程篇
wait 和 sleep 的区别
- wait 方法必须在 synchronized 保护的代码块中,而 sleep 方法并没有这个要求
- wait 方法会主动释放 monitor 锁,在同步代码块中执行 sleep 方法时,并不会释放 monitor 锁
- wait 方法意味着永久等待,直到被中断或被唤醒才能恢复。sleep 方法中会定义一个时间,时间到期后会主动恢复
- wait / notify 是 Object 类的方法,而 sleep 是 Thread 类的方法
线程创建方式
- 实现 Runnable 接口 (优先使用)
- 实现 Callback 接口 (有返回值可抛出异常)
- 继承 Thread 类
- 使用线程池 (底层都是实现 run 方法)
线程池参数
优点:通过复用已创建的线程池,降低资源消耗、线程可以直接处理队列中的任务加快响应速度、同时便于统一监控和管理。
| 参数名 | 描述 | 默认值 |
|---|---|---|
corePoolSize | 线程池中的核心线程数。即使线程处于空闲状态,也会保持在池中,除非设置了 allowCoreThreadTimeOut 为 true。 | N/A |
maximumPoolSize | 线程池中允许的最大线程数。如果任务数量超过这个数值,则会根据拒绝策略处理这些任务。 | N/A |
keepAliveTime | 当线程数大于核心线程数时,这是多余的空闲线程等待新任务之前活动的最长时间。 | 60秒 |
unit | keepAliveTime参数的时间单位,可以是纳秒、微秒、毫秒、秒、分、小时或天等。 | 秒 |
workQueue | 用于保存等待执行的任务的队列,通常是BlockingQueue类型的实例。 | N/A |
threadFactory | 用于设置创建线程的工厂,可以通过自定义ThreadFactory来设置线程名称、是否守护线程等属性。 | 默认工厂 |
handler | 当线程和队列都满时,新的任务将根据此处理器进行处理。通常有四种预设策略:抛出异常、直接由调用线程运行、丢弃一个旧任务或丢弃当前任务。 | 抛出异常 |
线程池任务分配流程
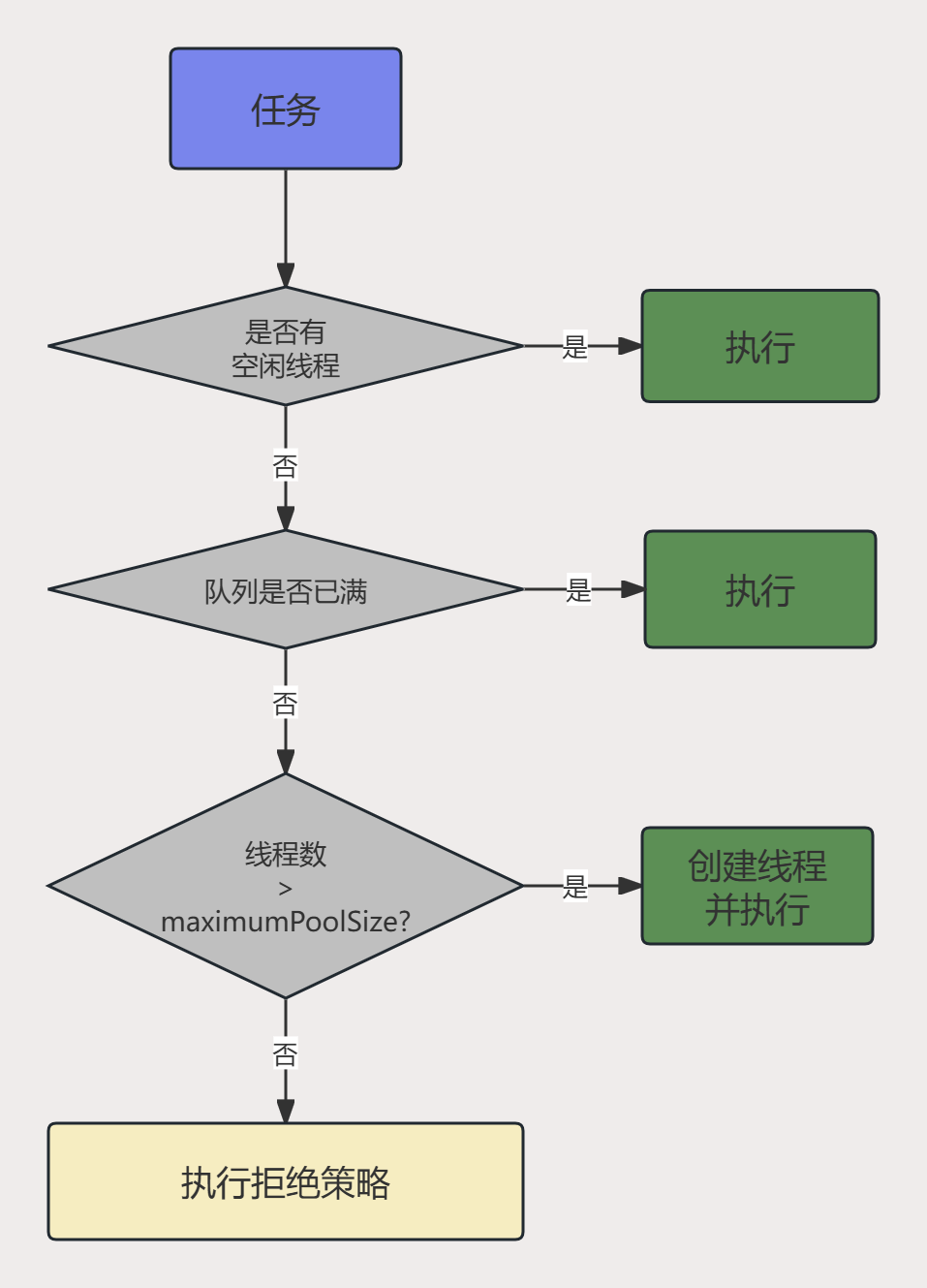
- 当线程池大小 小于 corePoolSize,新提交任务将创建一个新线程执行任务,即使此时线程池中存在空闲线程
- 当线程池大小达到 corePoolSize 时,新提交任务将被放入 workQueue中,等待线程池中任务调度执行
- 当 workQueue 已满,且当前线程池中线程数 小于 maxnumPoolSize 时,新提交任务会创建新线程执行任务
- 当已提交但未被处理完成的任务数 大于 maxnumPoolSize 时,新提交任务由 RejectedExecutionHandler 处理
- 当线程池中线程数超过 corePoolSize 时,并且部分线程的空闲时间到达 keepAliveTime 时,空闲线程将被关闭,直到数量 小于等于 corePoolSize
TIP
在Java的线程池实现中(如ThreadPoolExecutor),并没有严格区分“核心”线程和“非核心”线程的身份标识。所谓的“核心线程数”更多是指线程池应该维持的最小线程数量,即使这些线程是空闲的(除非设置了allowCoreThreadTimeOut(true)允许核心线程超时)。
任何超出corePoolSize并处于空闲状态超过指定时间的线程都可能被终止,以确保线程池内的线程数量符合预期的配置(核心线程数)。这意味着,最终哪些线程保持活跃状态,完全取决于任务调度的情况以及线程池的动态调整机制。
线程拒绝策略
线程池中的线程已经用完了,无法继续为新任务服务,同时,等待队列也已经排满了,再也塞不下新任务了。这时候就需要拒绝策略来处理这个问题。
- AbortPolicy(默认策略)
- 行为
直接抛出一个 RejectedExecutionException 异常,阻止系统正常运行。可以根据业务逻辑选择重试或者放弃提交等策略 - 适用场景
当你不希望忽略任何提交的任务,并且想要快速发现并处理这种错误情况时使用。
javaThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(2)); executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy()); - 行为
- CallerRunsPolicy
- 行为
只要线程池未关闭,由调用线程(通常是主线程)来执行当前在线程池中被丢弃的任务。不会造成任务丢失,同时减缓提交任务的速度,给执行任务缓冲时间。 - 适用场景
当你希望避免丢弃任务,并且能够承受调用线程执行额外任务带来的性能影响时。
- 行为
- DiscardPolicy
- 行为
直接丢弃不能处理的任务,不做任何通知或记录 - 适用场景
当你完全不关心被拒绝的任务是否得到处理,并且不想因为任务被拒绝而产生额外的开销时。
- 行为
- DiscardOldestPolicy
- 行为
丢弃队列中最旧的任务(也就是即将被执行的任务),然后尝试重新提交当前任务
- 行为
除了上述四种内置的决绝策略外,还可以通过实现 RejectedExecutionHandler 接口来自定义拒绝策略,根据自己的需求来决定如何处理被拒绝的任务
Executors类实现线程池
| 线程池类型 | 描述 | 特点 |
|---|---|---|
| Single Thread Executor | 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务。 | 所有任务按顺序运行;确保所有任务都在同一个线程中依次执行,线程结束后能重新创建新的线程来替代原来的。 |
| Single Thread Scheduled Executor | 创建一个单线程执行程序,能够调度命令在指定延迟后运行或者定期执行。 | 类似于ScheduledThreadPoolExecutor但使用单一线程;保证所有任务按序执行,并且是周期性和延迟任务的理想选择。 |
| Scheduled Thread Pool | 创建一个支持定时及周期性任务执行的线程池。 | 可以安排任务在给定延迟后运行,或定期执行;适用于需要计划执行任务的场景。 |
| Fixed Thread Pool | 创建一个拥有固定数量线程的线程池。 | 线程数固定,空闲线程会一直存在直到线程池被关闭;适用于负载较稳定的应用场景。 |
| Cached Thread Pool | 创建一个可根据需要创建新线程的线程池,但在以前构造的线程可用时将重用它们。 | 没有核心线程,最大线程数为Integer.MAX_VALUE;线程空闲60秒后会被回收;适合执行大量短期异步任务。 |