Redis数据类型与操作
String
简介
Redis 的 String(字符串) 是最基础、最灵活的数据类型,可存储文本、数值或二进制数据(如图片、序列化对象)。其设计兼顾高效读写与原子操作,是 Redis 中使用最广泛的数据类型。
常用命令
命令 | 解释 | 示例 | 备注 |
|---|---|---|---|
| SET | 为字符串键设置值 | set key value | |
| MSET | 一次为多个字符串键设置值 | mset key1 value1 key2 value2 | 要么同时成功,要么同时失败 |
| GET | 获取字符串键的值 | set key value get key | 返回结果:value |
| GETSET | 获取指定键的值并更新键值为新输入的值 | set key1 人之初,性本善 getset key1 性相近,习相远 | 返回结果:人之初,性本善 返回旧值并更新键值为新值,当再次执行 get key1 命令时将返回:性相近,习相远 |
| SETNX | 只在键不存在的情况下,为字符串键设置值 | 示例一 --之前未存储过键为key3的数据 setnx key3 value3 示例二 set key4 val4 setnx key4 newval4 | 结果: 示例一执行成功 示例二执行失败 如果之前已存储过键为key3的数据不论是set存储还是setnx存储,并且没有删除,则执行该命令不会成功 |
| MSETNX | 只在键不存在的情况下,一次为多个字符串键设置值 | msetnx key4 value4 key5 value5 | 要么同时成功,要么同时失败 |
| STRLEN | 获取字符串值的字节长度 | set key1 人之初,性本善 strlen key1 | 返回结果:21 UTF-8编码中一个汉字(包括中文标点)占用3个字节 |
| GETRANGE | 获取存储在键中的字符串值的一部分 | set key1 人之初,性本善 getrange key1 0 2 | 返回结果:人 key:要操作的字符串键。 start 和 end:子串的起始和结束索引(包含两端,支持负数索引)。 正数索引:从0开始,0表示第一个字节,1表示第二个字节,依此类推。 负数索引:从字符串末尾开始,-1表示最后一个字节,-2表示倒数第二个,依此类推。 越界处理: 若索引超出字符串长度,自动调整为有效范围。 若start > end,返回空字符串。 注意是按字节数截取的哦! |
| SETRANGE | 修改字符串类型键值对的指定位置内容 从指定偏移量开始覆写字符串值 | --命令一 set key1 马到成功 --命令二 get key1 --命令三 setrange key1 0 码 --命令四 get key1 | 返回结果: 命令二:马到成功 命令四:码到成功 命令三的含义是从第0个字节开始覆盖原值,注意偏移量0指的是字节哦 如果命令为 setrange key1 1 倒, 并不是将`到`字替换为`倒`字,而是从第一个字节开始覆盖,这样可能产生乱码 如果原字符串长度小于偏移量 offset,Redis 会用零字节填充原字符串末尾到 offset 之间的空白,再将 value 写入 比如原值为hello 执行命令 setrange key1 6 world 因为原值最大偏移量也就是5,所以会先以零字节补充直至偏移量达到6,而后再用value补充 最终结果为hello world,长度为11字节 键不存在时,视为空字符串处理,并根据 offset 和 value 生成新字符串 |
| APPEND | 用于向指定键(key)对应的字符串值末尾追加内容 | append key value | 若key不存在,Redis会将其视为空字符串,然后执行追加操作。效果等同于 set key value 注意:即使原值为数字形式,APPEND仍按字符串处理,而非数学加法。 |
| INCR | 用于对存储在指定键(key)中的整数值进行原子性递增操作 | incr key | 将键对应的值加1(仅限整数类型) 键不存在时,Redis会先将其值初始化为0,再执行INCR操作。最终结果为1 若key对应的值无法解析为整数(如字符串`abc`或浮点数3.14),Redis会返回错误:(error) ERR value is not an integer or out of range。 INCR是原子操作,适用于高并发场景(如计数器),确保线程安全 |
| INCRBY | 用于对指定键(key)存储的整数值进行原子性递增,并允许自定义递增步长 | INCRBY key increment | 将key对应的整数值增加指定步长(increment,必须为整数) 适合高并发场景(如积分累加) |
| INCRBYFLOAT | 对指定键(key)存储的数值(整数或浮点数)进行原子性递增,并支持浮点数步长 | INCRBYFLOAT key increment | 将key对应的数值增加指定步长(increment,可为整数或浮点数) 键不存在时,Redis会先将其值初始化为0.0,再执行递增操作 键存在但非数值,(如字符串`abc`),Redis返回错误:(error) ERR value is not a valid float 与INCR/INCRBY相同,INCRBYFLOAT是原子操作,适用于高并发场景(如实时统计) Redis内部使用IEEE 754双精度浮点数存储,精度约17位小数 支持负步增长 |
| DECR | 用于对存储在指定键(key)中的整数值进行原子性递减操作 | decr key | 将键对应的值减1(仅限整数类型) 键不存在时,Redis会先将其值初始化为0,再执行DECR操作。最终结果为-1 若key对应的值无法解析为整数(如字符串`abc`或浮点数3.14),Redis会返回错误:(error) ERR value is not an integer or out of range。 DECR是原子操作,适用于高并发场景(如库存扣减、实时计数器),确保线程安全 |
| DECRBY | 用于对指定键(key)存储的整数值进行原子性递减,并允许自定义递减步长 | decrby key decrement | 将key对应的整数值减少指定步长(decrement,必须为整数) 适合高并发场景(如秒杀库存扣减) DECRBY key N 完全等价于 INCRBY key -N |
Hash
简介
Redis 的 Hash(哈希表) 是一种用于存储字段-值(field-value pairs) 的数据结构,适合表示对象(如用户信息、商品属性)。它支持对单个字段的原子操作。
常用命令
命令 | 解释 | 示例 | 备注 |
|---|---|---|---|
| HSET | 为哈希表中的字段设置值可批量操作 | hset user:1000 name John age 30 | 若字段已存在则覆盖旧值,返回新增字段数量 Redis 4.0+支持批量操作 |
| HMSET | 批量设置哈希表中的多个字段值 已逐步被HSET取代 | hmset user:1000 name John age 30 email john@example.com | 原子性操作,要么全部成功,要么全部失败 |
| HGET | 获取哈希表中指定字段的值 | hget user:1000 name | 返回结果:John 若字段不存在返回(nil) |
| HMGET | 批量获取哈希表中多个字段的值 | hmget user:1000 name age | 返回结果: 1) John 2) 30 不存在的字段返回(nil) |
| HGETALL | 获取哈希表中所有字段和值 | hgetall user:1000 | 返回结果交替显示字段和值: 1) name 2) John 3) age 4) 30 大哈希表慎用(可能阻塞服务器) |
| HDEL | 删除哈希表中一个或多个字段 | hdel user:1000 email | 返回成功删除的字段数量(不存在的字段会被忽略) |
| HEXISTS | 检查哈希表中是否存在指定字段 | hexists user:1000 name | 返回1(存在) 返回0(不存在) |
| HINCRBY | 将哈希表中的整数字段值增加指定步长 | hincrby user:1000 age 5 | 返回新值:35 若字段不存在,先初始化为0再操作 非整数值会返回:(error) ERR hash value is not an integer |
| HINCRBYFLOAT | 将哈希表的数值字段(整数/浮点数)增加指定步长 | hincrbyfloat product:100 price 1.5 | 支持负步长,返回字符串形式的新值(如31.5) |
| HKEYS | 获取哈希表中的所有字段名 | hkeys user:1000 | 返回结果: 1) name 2) age 空哈希返回(empty list or set) |
| HVALS | 获取哈希表中的所有字段值 | hvals user:1000 | 返回结果: 1) John 2) 30 |
| HLEN | 获取哈希表中字段的数量 | hlen user:1000 | 返回结果:2 |
| HSETNX | 仅在字段不存在时设置哈希表字段的值 | 示例一 hsetnx user:1000 address New York 示例二 hsetnx user:1000 name David | 结果: 示例一成功(新增address字段) 示例二失败(name字段已存在) |
| HSCAN | 增量迭代哈希表中的字段/值(适用于大哈希) | hscan user:1000 0 match a* | 返回分页结果,匹配以a开头的字段 游标0表示迭代结束,非0值需继续迭代 |
List
简介
Redis的List结构说到底就是一个双向链表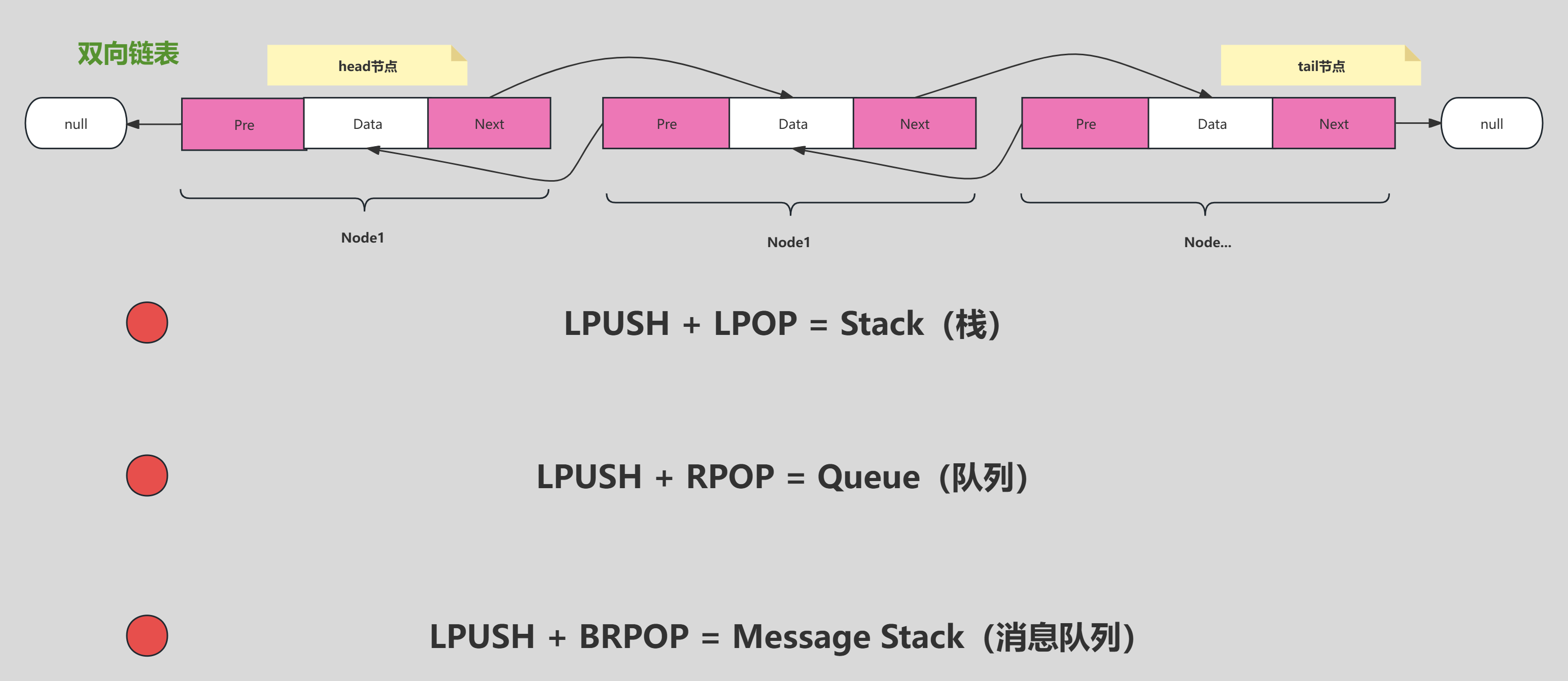
常用命令
命令 | 解释 | 示例 | 备注 |
|---|---|---|---|
| LPUSH | 将一个或多个值插入列表头部(左侧) | lpush mylist a b c | 返回操作后列表长度(如3) 若键不存在则自动创建新列表 多个元素按参数顺序插入,最终顺序为c b a |
| RPUSH | 将一个或多个值插入列表尾部(右侧) | rpush mylist x y z | 返回操作后列表长度(如6) 插入顺序为x → y → z,列表变为c b a x y z |
| LPOP | 移除并返回列表头部(左侧)第一个元素 | lpop mylist | 返回结果:c 列表变为:b a x y z 若列表为空返回(nil) |
| RPOP | 移除并返回列表尾部(右侧)最后一个元素 | rpop mylist | 返回结果:z 列表变为:b a x y 支持附加参数RPOP count N(Redis 6.2+批量弹出) |
| LRANGE | 获取列表中指定范围的元素 只是获取,元素还会存在List中 | lrange mylist 0 -1 | 返回所有元素: 1) b 2) a 3) x 4) y 索引规则: - 0表示第一个元素,-1表示最后一个元素 - 若end超出实际范围,自动截断到末尾 |
| LLEN | 获取列表长度 | llen mylist | 返回结果:4 若键不存在返回0 |
| LINDEX | 通过索引获取列表元素 | lindex mylist 2 | 返回结果:x 支持负数索引(如-1表示最后一个元素) 索引越界返回(nil) |
| LINSERT | 从列表头开始查找,查找到第一个与命令相同的元素,并在其前/后插入新元素 | linsert mylist BEFORE x java | 返回操作后列表长度(如5) 列表变为:b a java x y 若基准元素(pivot)不存在返回-1 BEFORE/AFTER参数不区分大小写 |
| LSET | 通过索引设置列表元素的值 | lset mylist 1 python | 操作后列表:b python java x y 索引越界返回错误:(error) ERR index out of range |
| LTRIM | 修剪列表,仅保留指定范围内的元素 | ltrim mylist 1 3 | 保留索引1到3的元素,列表变为:python java x 原列表被永久修改,常用于限制列表长度 |
| BLPOP | 阻塞式移除并返回列表头部第一个元素(支持多列表监控) | blpop list1 list2 10 | 若列表无元素,阻塞10秒等待数据 返回格式: 1) 列表名 2) 元素值 超时时间0表示无限阻塞 |
| BRPOP | 阻塞式移除并返回列表尾部最后一个元素(支持多列表监控) | brpop tasks 5 | 行为与BLPOP类似,操作方向相反 典型应用:任务队列消费者 |
| RPOPLPUSH | 原子性操作:从源列表尾部弹出元素,插入新目标列表头部 | rpoplpush source_list target_list | 若源列表为空返回(nil) 安全队列模式:处理任务时防止消费者崩溃丢失消息 |
Set
简介
Redis 的 Set(集合) 是一种基于哈希表实现的、存储无序且唯一的字符串元素的数据结构。它支持高效的集合运算(如交集、并集、差集),适用于需要去重或快速判断成员存在的场景。
- 唯一性
每个元素在 Set 中仅出现一次,自动去重 示例:SADD users "Alice" "Bob" "Alice" → 实际存储 ["Alice", "Bob"] - 无序性
元素没有固定顺序,不支持通过索引访问 - 高效操作
查询成员是否存在:SISMEMBER 时间复杂度 O(1)
常用命令
命令 | 解释 | 示例 | 备注 |
|---|---|---|---|
| SADD | 向集合中添加一个或多个成员 | sadd myset apple banana cherry | 返回成功添加的成员数量(重复成员不计入) 若键不存在则自动创建新集合 时间复杂度:O(N),N为添加的成员数 |
| SREM | 移除集合中一个或多个成员 | srem myset apple banana | 返回成功移除的成员数量 不存在的成员会被忽略 |
| SMEMBERS | 获取集合中所有成员 | smembers myset | 返回结果无序(集合无序存储) 大集合慎用(可能阻塞服务器),建议使用SSCAN分页获取 |
| SISMEMBER | 检查指定成员是否存在于集合中 | sismember myset cherry | 返回结果: 1(存在) 0(不存在) 时间复杂度:O(1) |
| SCARD | 获取集合的成员数量 | scard myset | 键不存在时返回0 |
| SPOP | 随机移除并返回集合中的一个或多个成员 | spop myset spop myset 2 | 默认移除1个成员,Redis 3.2+支持批量移除 集合为空时返回(nil) |
| SRANDMEMBER | 随机返回集合中的一个或多个成员(不移除) | srandmember myset srandmember myset 3 | 默认返回 1 个成员 正数参数返回不重复元素 负数参数允许返回重复元素(如`srandmember myset -5`) |
| SINTER | 返回多个集合的交集 | sinter set1 set2 | 返回所有集合共有的成员 时间复杂度:O(N*M),N为最小集合大小,M为集合数量 |
| SINTERSTORE | 将多个集合的交集存储到新集合中 | sinterstore new_set set1 set2 | 返回新集合的成员数量 |
| SUNION | 返回多个集合的并集 | sunion set1 set2 | 时间复杂度:O(N),N为所有集合的总成员数 |
| SUNIONSTORE | 将多个集合的并集存储到新集合中 | sunionstore new_set set1 set2 | 目标集合已存在则覆盖内容 |
| SDIFF | 返回第一个集合与其他集合的差集 | sdiff set1 set2 | 返回结果: set1中独有且不在set2中的成员 |
| SDIFFSTORE | 将差集存储到新集合中 | sdiffstore new_set set1 set2 | 常用于数据过滤场景 |
| SMOVE | 将成员从源集合移动到目标集合 | smove source_set dest_set apple | 原子性操作 若源集合不存在该成员,返回0则不执行任何操作 目标集合不存在则自动创建 |
| SSCAN | 增量迭代集合中的成员(适用于大集合) | --返回匹配以b开头的成员 sscan myset 0 match b* | SSCAN key cursor [MATCH pattern] [COUNT count] cursor: 游标值,用于迭代过程中的位置标记。 初始调用时应使用 0 作为游标值,随后每次调用返回的游标值应用于下一次调用,直到游标返回为 0 表示遍历结束 MATCH pattern: 可选参数,用于过滤匹配特定模式的元素 COUNT count: 可选参数,提示 SSCAN 每次迭代返回的大致元素数量。 注意,这只是一个提示,实际返回的数量可能有所不同 |
SortedSet
简介
Redis 的 Sorted Set(有序集合) 是一种结合了 Set(唯一性) 和 有序列表(排序能力) 特性的数据结构。每个元素关联一个 score(分数值),通过分数实现自动排序,同时保证元素的唯一性。
- 有序性 元素按 score 升序排列(默认),相同 score 的元素按字典序排序 示例:ZADD ranking 95 "Alice" 80 "Bob" 95 "Charlie" → 排序后为 Bob (80), Alice (95), Charlie (95)
- 唯一性 元素(成员)唯一,但 score 可重复
- 高效范围操作 支持基于 score 或字典序的范围查询(如排名、分页),时间复杂度低至 O(log N)
- 混合存储 既能通过 score 操作,也能像 Hash 一样通过元素值直接访问
常用命令
命令 | 解释 | 示例 | 备注 |
|---|---|---|---|
| ZADD | 向有序集合添加一个或多个成员(或更新分数) | zadd leaderboard 100 Alice 95 Bob | 返回新增成员数量(重复成员会更新分数) 支持选项: - NX:仅新增成员(不更新现有成员) - XX:仅更新现有成员(不新增) - CH:返回被修改成员总数(新增+更新) - INCR:分数递增(类似ZINCRBY) |
| ZRANGE | 按分数升序返回指定索引范围的成员 | zrange leaderboard 0 -1 WITHSCORES | 返回结果: 1) Bob 2) 95 3) Alice 4) 100 参数说明: 0 -1:表示返回全部成员 WITHSCORES:同时返回分数 |
| ZREVRANGE | 按分数降序返回指定索引范围的成员 | zrevrange leaderboard 0 1 WITHSCORES | 返回结果: 1) Alice 2) 100 3) Bob 4) 95 常用于排行榜TOP N查询 |
| ZRANK | 获取成员在有序集合中的升序排名(从0开始) | zrank leaderboard Alice | 返回结果:1(Alice在升序排名第2位) |
| ZREVRANK | 获取成员在有序集合中的降序排名(从0开始) | zrevrank leaderboard Alice | 返回结果:0(Alice在降序排名第1位) |
| ZSCORE | 获取指定成员的分数 | zscore leaderboard Alice | 返回结果:100(字符串形式) |
| ZINCRBY | 为指定成员的分数增加增量值 | zincrby leaderboard 5 Alice | 返回新分数:105 若成员不存在,视为初始分数0并执行操作 |
| ZREM | 移除有序集合中的一个或多个成员 | zrem leaderboard Bob | 返回成功移除的成员数量 |
| ZCOUNT | 统计分数在指定区间内的成员数量 | zcount leaderboard 90 100 | 返回结果:2(Alice和Bob) 区间表示: - 90:表示大于90 - 100:表示小于等于100 |
| ZCARD | 获取有序集合的成员总数 | zcard leaderboard | 键不存在时返回0 |
| ZRANGEBYSCORE | 按分数升序返回指定分数范围的成员 | zrangebyscore leaderboard 90 100 WITHSCORES | 等价于ZRANGE配合BYSCORE参数 支持无限区间:-inf +inf |
| ZREMRANGEBYRANK | 移除指定排名范围的成员 | zremrangebyrank leaderboard 0 0 | 移除升序排名第1的成员(如Bob) |
| ZREMRANGEBYSCORE | 移除指定分数范围的成员 | zremrangebyscore leaderboard 0 90 | 移除分数<=90的成员 |
| ZPOPMAX | 移除并返回分数最高的成员(Redis 5.0+) | zpopmax leaderboard 2 | 可指定移除数量(默认1个) |
| BZPOPMAX | 阻塞式移除并返回分数最高的成员(Redis 5.0+) | bzpopmax leaderboard 2 | 可指定移除数量(默认1个) |
| ZPOPMIN | 移除并返回分数最低的成员(Redis 5.0+) | zpopmin leaderboard | 默认移除1个成员 |
| BZPOPMAX | 阻塞式移除并返回分数最高的成员(Redis 5.0+) | bzpopmax leaderboard 2 | 可指定移除数量(默认1个) |
| ZUNIONSTORE | 将多个有序集合的并集存储到新集合 | zunionstore new_set 2 set1 set2 WEIGHTS 2 3 | 支持权重计算: 成员最终分数 = (set1分数*2) + (set2分数*3) AGGREGATE选项:SUM(默认)/MIN/MAX |
| ZINTERSTORE | 将多个有序集合的交集存储到新集合 | zinterstore new_set 2 set1 set2 | 权重和聚合规则与ZUNIONSTORE相同 |